Dinesh Kumar A SApache Spark Optimisation-Part 1Writing an efficient Spark program is mandatory for achieving better performance and not to spend unncessarily on the cost of infraNov 15, 20227Nov 15, 20227
Subham KhandelwalPySpark — The Factor of CoresDefault Parallelism is a very standout factor in Spark executions. Basically its the number of tasks Spark can raise in parallel and it…Oct 28, 2022262Oct 28, 2022262
InTDS ArchivebySimon Grah6 recommendations for optimizing a Spark jobA guideline of six recommendations that are quickly actionable for optimizing a Spark job.Nov 24, 20218469Nov 24, 20218469
Justin DavisPyspark — Filter asap to Reduce run timeIs your spark job taking a long time to run? Is the process bar just slowly creeping along? Many times people blame slow jobs on memory…Aug 12, 202257Aug 12, 202257
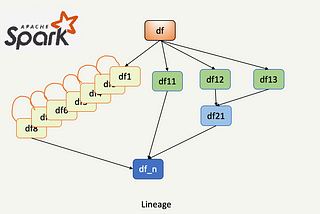
InThe ByteDoodle BlogbyHareesha DandamudiApache Spark — Large query plansSpark achieves its fault tolerance with ability to go back and replay everything from DAG. But if lineage of some of those dataframes…Apr 22, 202271Apr 22, 202271
InThe StartupbySivaprasad MandapatiSpark Parallelization Key FactorsSpark is an unified analytics engine for Bigdata Processing, with built-in modules for ETL,Streaming,SQL,Machine Learning and Graph…Jan 30, 2021175Jan 30, 2021175