PinnedBook series – Designing data intensive Application by Martin kleppmannHi thereJul 26, 2021Jul 26, 2021
Optimise Clustering in BigQueryWhen it comes to clustering in a table, the best approach will depend on the specific table and the queries that will be run against it…Jul 31, 2023Jul 31, 2023
DataFlow TutorialGoogle Cloud Dataflow is a fully managed service for executing Apache Beam pipelines within the Google Cloud Platform (GCP). It provides a…May 9, 2023May 9, 2023
BigQuery Tutorial With ExampleHere are a few examples illustrating how to ingest data into BigQuery using different methods, presented in a publishing format:May 9, 2023May 9, 2023
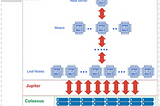
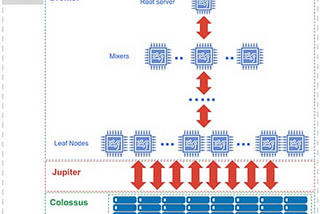
Big Query in 5 partsBigQuery is a fully-managed, serverless data warehouse offered by Google Cloud Platform. It enables super-fast SQL queries using the…May 8, 2023May 8, 2023
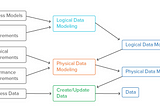
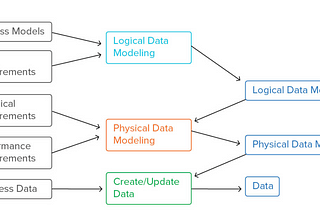
Data Modelling in depthData modeling is the process of creating a visual representation of the structure, relationships, and constraints of data in a system. It…May 8, 2023May 8, 2023
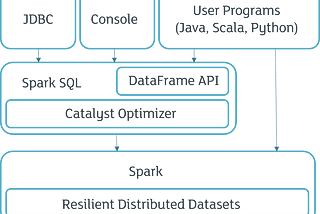
Spark CatalystSpark SQL is an Apache Spark module for structured data processing. One of the big differences with the Spark API RDD is that its…Aug 13, 2021Aug 13, 2021
Chapter 5 (Part 2) — Replication (Designing Data Intensive Applications)Here are my notes (Part-II) from the fifth chapter of the book — Designing Data-Intensive Applications by Martin Kleppmann.Jul 29, 20211Jul 29, 20211
Chapter 5 (Part 1) — Replication (Designing Data Intensive Applications)Here are my notes from the fifth chapter of the book — Designing Data-Intensive Applications by Martin Kleppmann.Jul 27, 2021Jul 27, 2021
OLAP vs. OLTP (Chapter 3 — Designing Data-Intensive Applications)Here are my notes from the third chapter of the book — Designing Data-Intensive Applications by Martin Kleppmann.Jul 27, 2021Jul 27, 2021